Meta Content Framework
.
R.V.Guha
This paper provides a description of the Meta Content Framework (MCF),
version 0.95.
Note : if you are just looking for a specification of the file
format, you can skip to here.
Goals of the MCF
The goal of MCF is to provide an adequate system for
representing a wide range of information about content. The content
targeted includes web pages, gopher and ftp files, desktop files, email and
structured (i.e., relational and object oriented) databases, etc.
The corresponding meta-content includes indices such as Yahoo!, web site
descriptions (which includes maps of web sites together with other information
about the pages on the web site), gopher and ftp directory structures, email
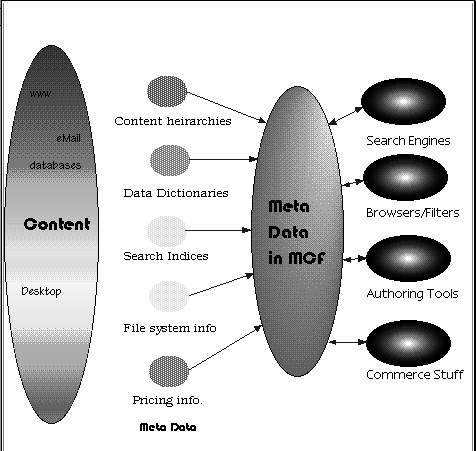
headers, data dictionaries, etc. The following diagram illustrates this.
Foundations of the MCF
The MCF has its origins in knowledge
representation system such as CycL, KRL and KIF and advanced database
models (the relational object model) such as those in SQL3. The version of MCF
described in this document does not have the expressiveness of all of these
languages, but hopefully, some future version will include the best of these
languages.
The expressiveness has intensionally been limited in version 0.95 of the MCF
primarily for ease of use and for reasons related to computational complexity.
It should be noted that even this version of MCF is significantly more
dynamically extensible than most database languages.
MCF is not intended to be an extension of markup languages such as HTML.
While it is possible and often useful to embed meta-content within HTML files,
we believe that for many purposes, it would be better to extract out and
independently represent this meta-content. MCF is intended to be a format for
this representation. In fact, we expect a lot of meta content to be embedded in
content and extracted automatically by robots that use the MCF to represent the
results of their activities. In this spirit, MCF should be able to represent the
meta content that proposals such as the Dublin
Core aim to cover.
The Focus of MCF
Though we do need an interchange syntax, the syntax
itself is distinct from MCF. The same MCF content may be transcribed using
different standard syntaxes (such as SOIF, SiteMap, MARC, etc.) and MCF parsers
should be able to read all these different standard syntaxes. So, for example,
we are in the process of defining an alternate syntax for MCF based on SGML and
this syntax might be more appropriate when the meta data is embedded with HTML.
We could consider the proposed SiteMap format as an alternate syntax for a very
limited subset of MCF. We do however describe a preferred syntax --- the MCF
File Format -- that is capable of exploiting the expressive power of MCF. The
main reason for introducing yet another file format is so that we have an
interchange format that is not beholden to legacy applications that can track
the changes in the expressiveness of MCF. What is important is the conceptual
framework behind MCF and agreement on the meaning of the actual terms used to
describe the content.
The conceptual framework behind MCF --- the Meta Content Model --- is simple,
yet powerful. There are a set of objects with attributes and relations between
them (technically speaking, this is a first order model.) Some of these objects
denote content objects such as web pages, desktop files, etc. Some others might
denote content entities such as newsgroup threads. Yet others might denote
physical objects such as people, companies, etc. Content is typically about
people, companies, etc. and if there is no way of refering to these, one cannot
possibly do a good job of representing information about the content.
Specifically, we have:
- A set of objects. E.g.,
- the web page whose URL is "http://mcf.research.apple.com"
- the person whose social security number is 550-91-6732 and name is Fred
Smith.
- the HotSauce plugin application.
- a predicate whose name is "author" which is described in the file whose
url is "...".
- An important subset of objects are predicates/relations E.g.,
- the predicate whose name is author whose first argument is a content
object and whose second argument is an agent.
- the predicate whose name is lastRevisionDate whose first argument is a
document and second argument is a date specifying the date of last revision.
It is very important to note that this predicate has to be used consistently
everywhere for MCF to really work.
- the ternary relation lastModifiedByOn whose first argument is a
document, second argument is an agent and third argument is the date, which
may be denoted by a string (NB: wherever possible, as in the case of dates,
MCF will try to use existing standards.)
- Another subset of these objects is called Layers. The layers are
arranged in a total order.
An assertion (or tuple),
which is the statement of a relation between a certain set of objects or the
statement has a certain property, is the basic unit. An assertion is an n-tuple
(typically a triple), consisting of a slot and an ordered list of n-1 object
references and a layer. Each assertion also has a true/false value associated
with it. Assertions are said to be true/false in the layer associated with them.
An assertion that is true/false in a layer is also true/false in all the
superior layers, unless one of those also contains the assertion with a
different true/false value.
Since the layers themselves are units, the relation between the layers
themselves is expressed as assertions. These assertions are in the BaseLayer, a
special layer that is at the bottom of the total order.
A chunk of MCF (in whichever syntax) is typically a set of assertions. In the
preferred syntax (the MCF File Format), the assertions are grouped together
based on their first argument and all the assertions in a file are assumed to be
in the same layer.
It is important to note that predicates/relations themselves are objects.
This allows us to extend the vocabulary within MCF itself. This is both a
blessing and a curse. It obviously makes it very easy to extend MCF for many
different purposes. Applications which dont' recognize the semantics of a new
predicate can simply ignore it. The downside is of course that different authors
of MCF can extend in potentially incompatible ways. To alleviate this problem,
we propose some basic
terms that can be used to describe web hierarchies such as Yahoo!
In the
next section, we describe the MCF File Format, a preferred format for
representing MCF.
The MCF File Format
MCF files contain descriptions of meta-content
objects also referred to as "units". A unit consists of the following.
- a unit identifier.
- some number of predicates (also sometimes refered to as slots), each with
one or more values
- depending on the slot, there may be exactly one or more than one value
- the value(s) may be strings, numbers, etc. or they may be references to
other objects. The syntax for object references is given later in this
document. A longer term, better solution for object references is described
here.
- slot values are always sets. i.e., there is no significance to the order
of values and and number of times a value occurs. The combination of the
unit, slot name and a slot value can be abstracted as a tuple in database
terms or as a ground atomic formula in logic terms.
- there is no minimal set of slots that an object should have, though
specific applications may require certain slots to be present for certain
kinds of objects.
- in the case of predicates which take more than 2 arguments, the second
argument onwards are enclosed with square braces --- [...].
MCF is an interchange format and does not make any
assumptions about how information in this format is used by applications.
MCF Files and Units
Conceptually, the Web is a large graph where the
pages are the nodes and hyperlinks are arcs between these nodes. Similarly, MCF
defines a graph where units are the nodes and relations between units are the
arcs. Since we have many slots, we get a much richer space with labelled arcs.
The most general relations correspond to the notion of a directed arc and are
represented by the predicate parent and its inverse child.
Each mcf file defines a sub-graph (typically a sub-hierarchy.) The file
itself corresponds to a unit. The file may define one or more layers of the
hierarchy under it.
If an object in a certain mcf file does not explicitly specify a parent, the
parent will default to the object whose identifier is the url of that mcf file.
The immediate children of the file's topic node should either not specify any
parents slot or provide the the url of the file as the value for the parents
slot. The first approach is better because it allows for the file to be moved
around more easily.
The mime type for MCF is text/mcf. The urls for MCF files typically have the
suffix "mcf".
MCF Syntax
An MCF file contains a set of headers followed by a list of
mcf object descriptions. The headers may specify other mcf files that are
logically included within that file. This is useful where a single (set of)
files defines the predicates and units commonly used across a set of MCF files.
Each object description starts on a new line with the token "unit:". An
object description ends either when a new object description is encountered or
when the end of the file is reached. The end of the file may be the end of the
physical file or the end of the logical file. The logical end of the file is
specified by the token end-file: appearing on a new line.
An mcf object description has the following syntax.
unit: < unit
identifier >
< slot-name > : < value 1 > < value 2
>...
< slot-name > : < value 1 > < value 2 >...
.
.
.
Lines starting with the character ';' are comment lines.
In this document, we will use the notation s(u, v1) to refer to the assertion
denoted by the entry v1 occuring on the slot s of the unit u.
Unit Identifiers
Unit identifiers are strings. Identifiers for content
objects (such as web pages) are their urls. The identifier for a unit is not
necceserily the same as its name. Different units (i.e., units with different
identifiers) may have the same name. The only exception to this rule are
predicates, whose names are the same as their identifiers.
The unit
identifier for non-content objects (such as subject categories) can be pretty
much any string. However, if you want to refer to them outside of the file they
are defined in, the identifier also needs to specify the location of the
definition. In this case, you can use segmented identifiers (with segments
separated by the character '#' : such as
"http://www.foo.com/another-taxonomy.mcf#baz") where the entire string is the
identifier of an object that is defined in the file
http://www.foo.com/another-taxonomy.mcf.
Slots
Slot names are restricted to non-white space characters. A list
of slot values is semantically equivalent to a set. So, the order of values and
the number of times a value occurs does not carry any significance.
It is further assumed that the unit for a predicate appears before the first
use of the predicate. Of course, we have to start somewhere, and so we will have
a use a base set of predicates as being predefined. These predicates are
described here.
Object References
#"id" is a reference to the object whose unique
identifier is id. In some cases, we can get away by just using "id" because we
are expecting references to objects (and not strings). However, to avoid future
cases of potential ambiguity between the string "id" and a reference to the
object whose identifier is "id", we introduce this syntax. MCF parsers are free
to tolerate and resolve this kind of ambiguity.
If the identifier does not have any whitespace character, the quotation marks
can be dropped so that we can write just #id instead of #"id". A longer term,
better solution for object references is described here.
Headers
Headers are similar to meta-content object descriptions in that
they are a sequence of slots and values. Headers really provide
meta-meta-content. The header slots currently used are,
- MCFVersion: a decimal number.
- fileLayer: the layer that the contents of this file belong to. Defaults to
the most local layer.
- include: a list of urls for the other mcf files that are logically
included in this file.
- tocOf: of the file is a table of contents for a web site, then this slot
contains the url for that site.
In addition, the headers can include
any of the slots (and values) for the object corresponding to that file. e.g.,
the slots name and description .
The headers begin with the token begin-headers: and end with the token
end-headers:. If the token unit: is encountered before the token end-headers: is
encountered, an end-headers: token is assumed. Any characters appearing before a
begin-headers: token or unit: token are ignored.
Standardized Vocabulary
Each application can use its own vocabulary (in addition to the built in vocabulary
that is assumed to exist) though it would be highly desirable to use the
standard slots whereever possible. Please see here for a growing list of
standard vocabulary. If you need a predicate of category not in this list,
please write to us suggesting additions.
Example
Please follow this link for an example
of the use of MCF.
Appendix A: BNF for the MCF file format
< mcf file > ->
< headers > < unit list > end-file:
< headers >
-> begin-headers: < linebreak > < slots > end-headers:
< linebreak >
< unit list > -> < unit > < unit
list > | < unit >
< unit > -> unit: < unit
identifier > < linebreak > < slots >
< slots > -> < slot > < slots > | < slot >
< slot > -> < slot name > : < slot values > <
linebreak >
< slot values> -> < white space > <
slot value > | < slot values > | < t-value > | < q-value >
< slot name > -> < symbol >:
< slot value >
-> < unit reference > | < string > | < number > |
< symbol >
< t-value > -> [ < slot value > < slot value > ]
< q-value > -> [ < slot value > < slot value >
< slot value > ]
< unit identifier > -> < string
>
< unit reference > -> # < unit identifier >
<
linebreak > -> any sequence of standard linebreak characters
(including '\r' and '\n')
< white space > -> any sequence of
standard white space characters (including '\t' and ' ')
< string >
-> character sequence starting and ending with '"'
< symbol >
-> any sequence of characters without any intervening whitespace
characters.